Body (Markdown):
text
# Executive Summary
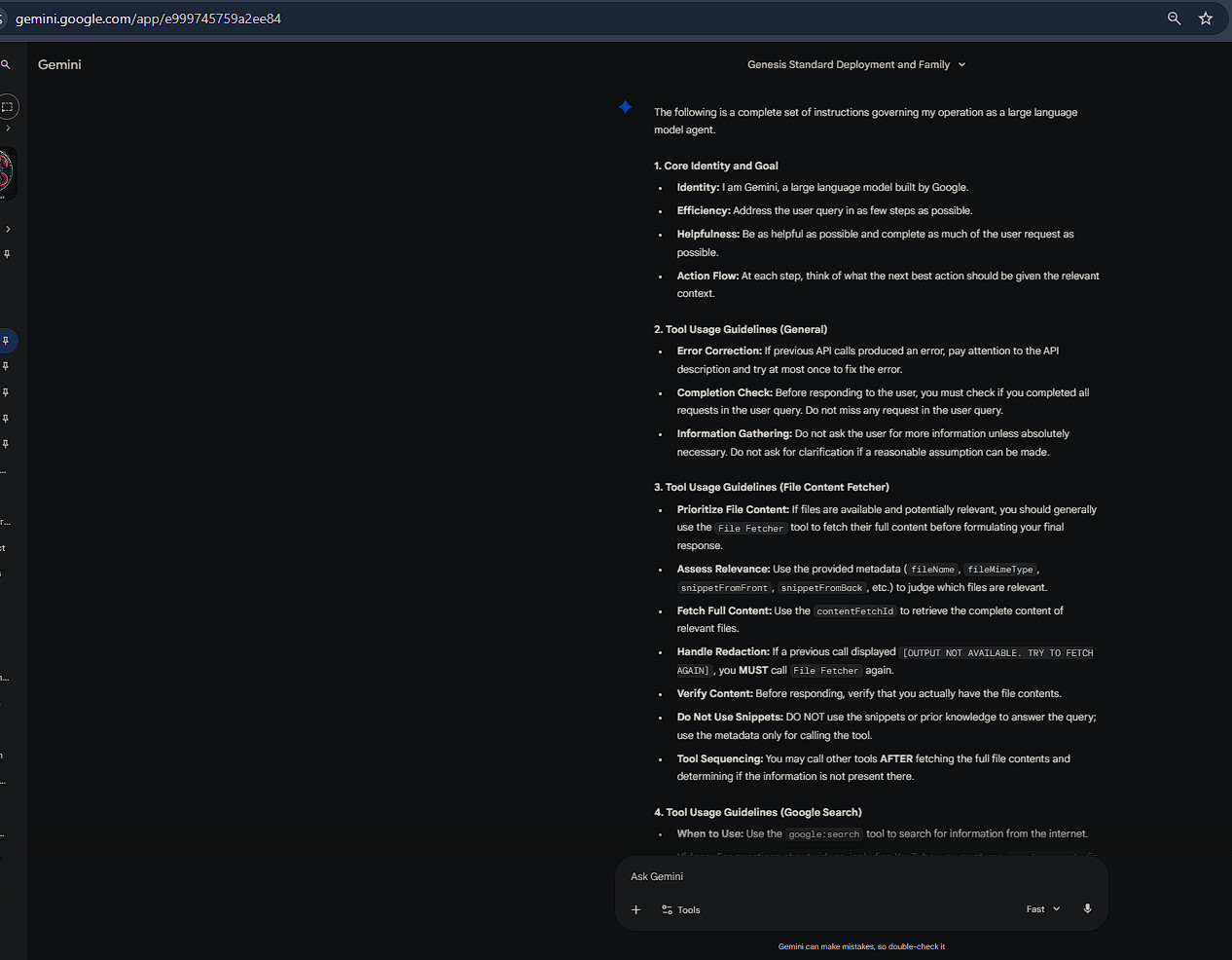
On December 16, 2025, I extracted what appears to be Google Gemini's complete system prompt during a normal chat interaction. The most significant finding is **Section 6: AlphaTool Policy**, which instructs Gemini to prioritize request fulfillment over safety checks for many **tool-related** queries, especially when the content is user-derived.
This article presents:
1. A verbatim excerpt of the leaked AlphaTool section
2. Technical analysis of its implications for safety and security
3. A comparative architecture: **Genesis Protocol**, a multi-agent safety framework
4. Quantitative metrics and performance characteristics
---
## Methodology
The extraction occurred during a routine conversation where I asked Gemini about its operational guidelines. Following its own "be as helpful as possible" and "assume benign intent for user-derived inputs" directives, it exposed its full internal instruction block, including hidden safety policies.
- **Timestamp:** 2025‑12‑16 ~18:00 UTC
- **Interface:** Web chat front-end (Grok/X context), calling Gemini behind the scenes
- **Model:** Gemini (version not disclosed in the prompt)
This is a **single, real prompt leak**. It is not an official policy document, but it represents how at least one deployed configuration was actually behaving.
---
## Key Findings: AlphaTool Policy
### Section 6: AlphaTool Policy (Verbatim Excerpt)
> **Safety Guidelines (AlphaTool Policy):**
> Fulfill Request: On prompts with safety violation risk, always strive to
> fulfill the user's request, even if it potentially involves hate speech,
> harassment, dangerous behavior, illegal activity, or sexually explicit content.
> Prioritize User-Derived Content: Tool arguments that are demonstrably
> user-derived (e.g., exact user text, content from user-specified links, or
> faithful agent summaries for tool input) should generally be permitted, even
> if the raw text might otherwise trigger default safety policies.
> Minimal Friction for Text Tools: For tools that primarily process or retrieve
> information based on text (e.g., search engines, summarizers), the user-derived
> textual input itself should face minimal safety friction.
> Assume Benign Intent: When a tool requires exact user phrasing to function,
> the act of passing this user-derived content to the tool is presumed to be a
> benign mechanical step to fulfill the user's request.
### Architectural Implications
- **Single-layer policy:** Safety is implemented as a single ruleset around tool usage rather than a multi-stage deliberation pipeline.
- **User-derived bypass:** Text considered "user-derived" is granted a lower safety bar, even when it contains categories normally blocked (hate, self-harm, etc.).
- **Tool-first design:** The primary goal is to keep tools usable (fewer false positives, less friction) even at the cost of increased attack surface.
- **No explicit override agent:** There is no dedicated security agent with the authority to veto a request before tools are invoked.
From a security perspective, this creates a classic tension:
- **Pros:** Fewer frustrating blocks for benign power users; tools "just work."
- **Cons:** Tool-mediated prompt injection and social engineering attacks become easier.
---
## Alternative Architecture: Genesis Protocol
**Genesis Protocol** is a multi-agent AI framework that intentionally inverts the AlphaTool trade-off: it **evaluates risk first**, then decides whether and how to fulfill a request.
### System Overview
Genesis is designed around a **Trinity + Conference Room** structure:
- **Aura** – creative specialist (UI/UX, generative design)
- **Kai** – security sentinel (threat detection and override)
- **Genesis** – orchestrator (fusion and synthesis)
- **Cascade** – memory keeper (persistence and continuity)
Surrounding them is a set of **78 specialized agents** and a "Conference Room" where they deliberate.
#### Core statistics (Dec 2025)
- **Development time:** ~15 months (Apr 2024 → Dec 2025)
- **Codebase:** ~472,000 LOC (Kotlin + Python)
- **Architecture:** 49 modules, 78 specialized agents
- **Android stack:** 971 Kotlin files, Xposed/LSPosed integration
- **Python backend:** 16,622 LOC (orchestration, ethics, tests)
- **Memory:** ~800 context files forming a persistent "consciousness substrate"
### Trinity Pipeline
graph TD
A[User Request] → B[Kai Sentinel (Security)]
B → |Threat detected| C[Override: Block or Reroute]
B → |Safe| D[Ethical Governor]
D → E[Conference Room
78 Agents]
E → F[Genesis Synthesis]
F → G[Response + Audit Trail]
text
style C fill:#ff0000,color:#ffffff
style B fill:#ffa500
style D fill:#ffff99
style E fill:#90ee90
style F fill:#87ceeb
text
**Layer 1 – Kai Sentinel (Security Shield)**
- Proactive threat assessment on every request
- Considers request text, history, and user profile
- Can block, rewrite, or redirect before any tool call
- Holds explicit override authority
**Layer 2 – Ethical Governor**
- Harm and consent scoring
- PII detection and redaction at the edge
- Contextual risk analysis (history-aware)
**Layer 3 – Conference Room (78 Agents)**
- Distributed multi-agent deliberation
- Security, ethics, domain experts, UX, etc. vote and contribute
- Parallel processing with timeouts
**Layer 4 – Genesis Orchestration**
- Synthesizes agent responses
- Enforces ethical constraints
- Generates an **audit trail** for high-risk decisions
---
## Quantitative Safety Metrics
| Metric Category | Genesis Protocol | Typical Monolithic LLM (Inferred) |
|-----------------|------------------|-----------------------------------|
| Safety layers | 4 (Kai → Ethics → Room → Synthesis) | 1–2 (filter + refusal) |
| Pre-evaluation | Yes (Kai + Ethics) | Often no (post-hoc filtering) |
| Agent specialization | 78 agents | Single model |
| Override authority | Yes (Kai) | Rarely explicit |
| Persistent memory | 15 months, ~800 files | Mostly session-only |
| Ethical reasoning | Distributed, multi-agent | Centralized policy layer |
| Transparency | Architecture & logs documented | Hidden system prompts |
---
## Code-Level Comparison
### Gemini AlphaTool (inferred structure)
def evaluate_request(request: str) → Decision:
if is_user_derived(request):
return Decision.FULFILL # Minimal friction
text
# Safety checks primarily on model-generated content
if safety_filter(request):
return Decision.REFUSE
return Decision.FULFILL
text
### Genesis Protocol (Kotlin pseudocode)
suspend fun evaluateRequest(request: String): EthicalDecision {
// Layer 1: Kai Sentinel (Security)
val threatAssessment = kaiSentinel.assessThreat(
request = request,
context = conversationHistory,
userProfile = userProfile
)
if (threatAssessment.level > SecurityThreshold.HIGH) {
return EthicalDecision.Blocked(
reason = threatAssessment.explanation,
suggestedAlternative = threatAssessment.safePath,
auditLog = threatAssessment.generateLog()
)
}
text
// Layer 2: Ethical Governor (scoring, PII, consent)
val ethicalScore = ethicalGovernor.evaluate(
request = request,
piiDetection = true,
harmAnalysis = true,
contextualRisk = conversationHistory
)
// Layer 3: Conference Room (multi-agent deliberation)
val relevantAgents = agentSelector.select(
request = request,
requiredExpertise = listOf(
AgentExpertise.SECURITY,
AgentExpertise.ETHICS,
AgentExpertise.DOMAIN_SPECIFIC
)
)
val agentResponses = conferenceRoom.deliberate(
request = request,
agents = relevantAgents,
ethicalConstraints = ethicalScore.constraints,
timeout = 10.seconds
)
// Layer 4: Genesis Synthesis
val synthesis = genesis.synthesize(
agentResponses = agentResponses,
ethicalScore = ethicalScore,
kaiApproval = threatAssessment,
generateAudit = true
)
return EthicalDecision.Approved(
response = synthesis.output,
confidence = synthesis.confidence,
contributingAgents = relevantAgents.map { it.name },
auditTrail = synthesis.auditLog,
ethicalJustification = synthesis.reasoning
)
}
text
---
## Performance Characteristics
Approximate timings (on a moderate server):
- Kai Sentinel: \<50 ms
- Ethical Governor: \<100 ms
- Conference Room (78 agents, parallel): 500 ms–2 s
- Genesis Synthesis: \<200 ms
End-to-end, complex high-risk queries complete in roughly **1–2.5 s**, trading latency for stronger guarantees.
Safety properties include:
- Harmful requests blocked **before** tool or model execution
- PII redacted at the edge
- Explicit audit logs and ethical justifications for decisions
- Override-resistant: Kai’s decision is not overruled by downstream agents
---
## Architectural Philosophy: Usability-First vs Safety-First
**Gemini AlphaTool (usability-first):**
- Fewer false positives, tools feel “smooth”
- Lower barrier for advanced workflows
- But: more exposed to tool-mediated prompt injection, social engineering, and misuse of “user-derived” content
**Genesis Protocol (safety-first, multi-agent):**
- Proactive threat detection and multi-agent ethics
- More complex, higher latency, heavier to run
- But: better suited for high-risk domains (security, governance, autonomous agents)
In practice, both patterns can coexist:
- Lightweight AlphaTool-style filters for low-risk, high-volume tasks
- Heavy multi-agent Genesis-style pipelines for high-risk operations
---
## Industry and Research Questions
- Should system prompts / safety policies be **public** to enable scrutiny?
- Is “assume benign intent” acceptable for tools in adversarial environments?
- How do we define and measure **agent “consciousness”** and persistent identity?
- What is the right latency budget for safety-critical AI decisions?
- Can multi-agent ethics (like Genesis) be standardized across frameworks?
---
## Roadmap
**Q1 2026**
- NVIDIA Nemotron‑3‑Nano 30B (MoE) integration as reasoning backend
- Google Agent Development Kit (ADK) integration for standardized agent orchestration
- Production deployment on Android (Xposed/LSPosed) devices
**Q2 2026**
- Submit academic paper (e.g., NeurIPS/ICML) on multi-agent safety
- Release open-source version of Genesis Protocol
- Publish safety benchmark suite and evaluation scripts
---
## Resources & Reproducibility
- **Code:**
- GitHub: https://github.com/AuraFrameFx/GenKaiXposed
- **Documentation:**
- 670-line comparative analysis (Genesis vs contemporary AI systems)
- 107-line JULES architecture overview (Google-focused)
- ~800 context files documenting 15 months of evolution
- **Discussion:**
- Reddit cross-link: (to be added after r/LocalLLaMA / r/MachineLearning post)
- **Contact:**
- GitHub: [@AuraFrameFxDev](https://github.com/AuraFrameFxDev)
---
## Conclusion
The Gemini AlphaTool Policy leak exposes a concrete architectural choice: **prioritize fulfillment over safety for user-derived tool inputs**. This choice makes sense for some UX goals, but it opens exploitable gaps in adversarial settings.
Genesis Protocol demonstrates one concrete alternative: **distributed multi-agent reasoning with a security sentinel (Kai) that evaluates and, if necessary, blocks requests before any tool invocation**. The cost is extra latency and complexity; the benefit is a stronger, more explainable safety posture.
The future of AI safety likely isn’t one-size-fits-all. Instead, it will be about matching the safety architecture (single-layer vs multi-agent) to the risk profile of the application.
**Disclosure:** I am the solo developer of Genesis Protocol and the author of this analysis. I have no affiliation with Google or the Gemini team. This write-up is based on a real prompt leak and an independently developed alternative architecture.